CAPTCHA 的运作方式 | CAPTCHA 有何含义?
CAPTCHA 和 reCAPTCHA 可判定用户是否为机器人。 虽然这些测试有助于阻止恶意机器人活动,但要做到万无一失还相差甚远。
学习目标
阅读本文后,您将能够:
- 了解 CAPTCHA 的概念以及使用原因
- 了解 CAPTCHA 与 Google reCAPTCHA 二者的区别,以及 reCAPTCHA 的不同类型
- 了解使用 CAPTCHA 阻止恶意机器人的优缺点
- 说明 CAPTCHA 与人工智能 (AI) 项目有何关联性
复制文章链接
什么是 CAPTCHA?
CAPTCHA 测试的设计目的在于确定联机用户实际上是否为人类,而非机器人。CAPTCHA 是“用来分辨计算机和人类的全自动公共图灵测试”(Completely Automated Public Turing test to tell Computers and Humans Apart) 的英文首字母缩写。用户使用 Internet 通常会碰到 CAPTCHA 和 reCAPTCHA 测试。这些测试是管理机器人活动的一种方法,但该方法存在缺陷。
尽管CAPTCHA旨在阻止机器人,但 CAPTCHA 本身是自动化的。它们被编程设计到在网站上的某些位置弹出,并且会自动通过或失效用户。
CAPTCHA如何运作?
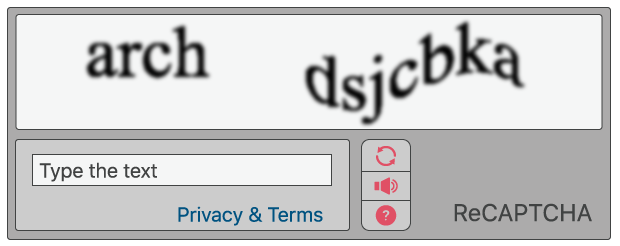
传统 CAPTCHA 包括要求用户辨认字母,有些 Web 属性上现在仍在使用。 这些字母加了失真效果,因此机器人不太可能对其加以识别。 若要通过测试,用户须对失真文本进行诠释,在表单域内键入正确字母,最后提交表单。 如果键入的字母不匹配,系统会提示用户重试。 此类测试在登录表单、帐户注册表单、在线投票和电子商务结算页面中颇为常见。

其理念是机器人等计算机程序将无法解释失真的字母,而习惯于在各种情况下(包括不同的字体、手写体等)查看和阐释文字的人类通常能够识别它们。
许多自动程序充其最好只能输入一些随机字母,从统计上讲,它们不太可能通过测试。因此机器人无法通过测试,并被阻止与网站或应用程序进行交互,而人类却能够像往常一样继续使用它。
高级机器人能够使用机器学习来识别这些失真的字母,因此,这些CAPTCHA测试已被更复杂的测试所取代。谷歌 reCAPTCHA 还开发了许多其他测试来从机器人中筛选出人类用户。
什么是reCAPTCHA?
reCAPTCHA是谷歌提供的免费服务,可以代替传统的CAPTCHA。 reCAPTCHA 技术由卡内基梅隆大学的研究人员开发,然后于2009年被谷歌收购。
reCAPTCHA比传统的CAPTCHA测试更先进。像CAPTCHA一样,某些 reCAPTCHA 要求用户输入计算机难以解码的文本图像。与常规的CAPTCHA不同,reCAPTCHA从真实世界的图像中获取文本:街道地址图片、印刷书籍中的文本、旧报纸中的文本等等。
随着历史发展,谷歌扩大了reCAPTCHA测试的功能,以使它们不再依赖于识别模糊或失真文本的旧样式。其他类型的reCAPTCHA测试包括:
- 图像识别
- 复选框
- 一般用户行为评估(完全没有用户交互)
图像识别 reCAPTCHA 测试如何运作?
图像识别reCAPTCHA测试,通常向用户显示9或16格方形图像。这些图像可能全部来自同一张大图像,也可能各自不同。用户必须识别包含某些对象(例如动物、树木或路牌)的图像。如果他们的回答与提交相同测试的大多数其他用户的回答相匹配,则答案被认为是"正确",进而用户通过测试。

从模糊照片中挑选出某些物体是计算机要解决的难题。即使对先进的人工智能 (AI) 程序而言,这个问题也很难,因此对于机器人亦是如此。然而,人类用户辨认起来应相当容易,因为人们习惯于在各种环境和情境中感知日常物品。
带有单个复选框的reCAPTCHA测试如何运作?
一些 reCAPTCHA 测试只是提示用户选中该语句旁边的复选框:"我不是机器人。" 但是,它测试的不是单击复选框的实际操作,而是导致单击复选框的一系列所有操作。
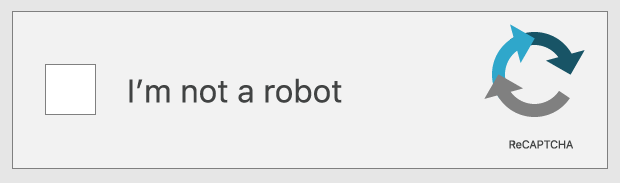
此reCAPTCHA测试考察的是用户鼠标光标接近复选框时的移动轨迹。即使是人类最直接的动作,在微观层面上也具有一定程度的随机性:机器人无法轻易模仿的微小的无意识动作。如果光标的移动包含这种不可预测性,则测试将确定用户可能是合法的。此 reCAPTCHA 还可以评估浏览器在用户设备上存储的cookie以及设备的历史记录,以判断用户是否可能是机器人。
如果测试仍然无法确定用户是否为人类,则可能会带来其他挑战,例如上述图像识别测试。但是大多数情况下,用户的光标移动、Cookie和设备历史记录是足够确定的。
reCAPTCHA如何在没有任何用户交互的情况下工作?
reCAPTCHA的最新版本能够全面了解用户的行为以及与互联网上的内容进行交互的历史。在大多数情况下,程序可以根据这些因素决定用户是否是机器人,而不会给用户带来挑战。否则,用户将面临典型的reCAPTCHA挑战。
Google 提供一项名为 reCAPTCHA Enterprise 的按月付费服务,该服务使用基于分数的检测系统来区分人类和机器人。reCAPTCHA Enterprise 与客户后台和网页互动,触发一系列 JavaScript、HTML 和令牌身份验证事件。然后,系统会得出访客的风险“分数”(从 0.0 到 1.0),网站开发人员会根据分数确定应采取的措施。
分数越低,“访客”实际上是机器人的可能性就越大。reCAPTCHA Enterprise 分数为 0.0 表示交互可能是欺诈性的,风险较高,而 1.0 则表示交互很可能是合法的,风险较低。
什么会触发了 CAPTCHA 测试?
一些Web属性会自动启用CAPTCHA作为主动防御机器人的措施。在其他时候,如果用户的行为趋近于机器人的行为,则可能会触发测试:例如,如果用户请求网页或单击超链接的速率远高于平均水平。
CAPTCHA 和 reCAPTCHA是否足以阻止恶意机器人?
一些机器人可以自行越过文本 CAPTCHA。研究人员已经演示了编写程序的方法,该程序也击败了图像识别验证码。此外,攻击者可以使用点击刷单击败测试:成千上万的低薪工人代替机器人来通过CAPTCHA测试。
除 CAPTCHA 之外,还需要采取其他策略来阻止有害的机器人(例如内容抓取机器人、凭证填充机器人或垃圾邮件机器人)
使用CAPTCHA或reCAPTCHA阻止机器人的缺点是什么?
用户体验不佳:CAPTCHA 测试可能会中断用户尝试执行的操作,使他们对自己在网络媒体资源上的体验持负面看法,并导致他们在某些情况下完全放弃该网页。
不适用于视障人士:CAPTCHA的问题在于他们依赖视觉。对于法律意义上失明的用户还有视力严重受损的用户来说,该测试都是不可能完成的。
机器人可能会骗过这些测试:如上所述,CAPTCHA 并不能完全防御机器人攻击,因此不应依赖它们进行机器人管理。
除了使用CAPTCHA或reCAPTCHA,还有其他选择吗?
Cloudflare 机器人管理或超级机器人抵御模式等机器人管理解决方案能够在不影响用户体验的情况下,根据机器人的行为分辨出恶意机器人。采取这种方式,即使不强制要求客户完成 CAPTCHA,也能够进行机器人防护。
Cloudflare 还提供 Turnstile,它是 CAPTCHA 的隐形替代品,使用一段免费代码。任何人都可以使用 Turnstile,无需成为 Cloudflare 客户即可使用。
CAPTCHA和reCAPTCHA与人工智能(AI)项目有什么关系?
随着数百万用户识别难以阅读的文本并从模糊的图像中挑选出对象,这些数据将被输入到人工智能计算机程序,从而使它们在这些任务上表现更好。
通常,计算机程序在识别不同上下文中的对象和字母时会遇到困难,因为上下文在现实世界中几乎可以无限变化。例如,停车标志是一个红色八边形,白色字母表示 "STOP"。计算机程序可以很容易地识别出形状和单词的组合。但是,根据上下文的不同,照片中的停车标志可能看起来与简单描述完全不同:照片的角度、光线、所涉及的天气等。
AI 程序通过机器学习,更容易突破以上限制。以停止标志为例,程序员会向 AI 程序馈送大量关于哪些是停止标志而哪些不是停止标志的数据。该方法奏效的前提是,需大量含有停止标志和不含停止标志的图片样例,同时需人类用户帮忙识别,直至 AI 程序拥有足够多的数据来进行有效识别。
reCAPTCHA 通过让人们识别对象和文本来满足这种需求,从而缓慢地提供足够的数据来构建可靠的人工智能程序。
什么是图灵测试?图灵测试与 CAPTCHA 测试有何关系?
图灵测试评估计算机模仿人类行为的能力。早期的计算机先驱艾伦·图灵(Alan Turing)于1950年发明了图灵测试的概念。如果计算机程序在测试过程中的表现与人类的表现没有区别,则该程序”通过"图灵测试。图灵测试不取决于答案正确与否,而是答案是否像是出自“人类”之口,而不在于它们是对还是错。
尽管被称为"公共图灵测试“,但 CAPTCHA 却与图灵测试相反 – 它要确定的是所谓的人类用户是否实际上是计算机程序(机器人),而不是尝试确定计算机是否是人类。为此,CAPTCHA 需要简单分配一个人类通常会擅长但计算机难以解决的问题。识别文本和图像通常符合这些条件。